背景
图片分库存储时,每一张图片都可以定位到特定的服务器
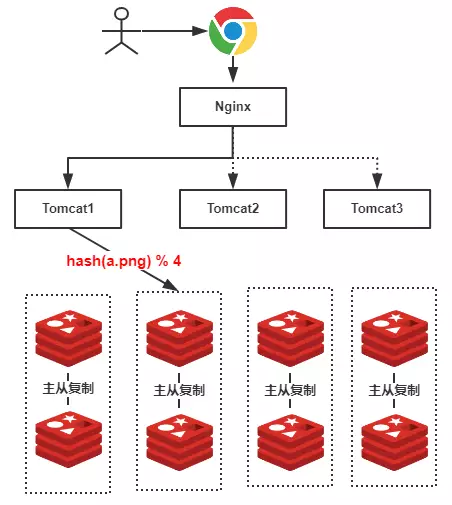
hash
上图中,假设我们查找的是”a.png”,由于有4台服务器(排除从库),因此公式为hash(a.png) % 4 = 2 ,可知定位到了第2号服务器,这样的话就不会遍历所有的服务器,大大提升了性能!
一切都运行正常,再考虑如下的两种情况;
- 一个 cache 服务器 m down 掉了(在实际应用中必须要考虑这种情况),这样所有映射到 cache m 的对象都会失效,怎么办,需要把 cache m 从 cache 中移除,这时候 cache 是 N-1 台,映射公式变成了 hash(object)%(N-1) ;
- 由于访问加重,需要添加 cache ,这时候 cache 是 N+1 台,映射公式变成了 hash(object)%(N+1) ;
1 和 2 意味着什么?
这意味着突然之间几乎所有cache 都失效了。缓存雪崩,这是一场灾难
一致性hash
有什么方法可以改变这个状况呢,这就是 consistent hashing
比如有{N0, N1, N2}三个节点,陆续有多个资源要分配到这三个节点上,如何尽可能均匀的分配到这些节点上
算法
一致性哈希算法的思路为:先构造出一个长度为2^32 整数环,根据N0-3的节点名称的hash值(分布为[0,2^32 -1])放到这个环上
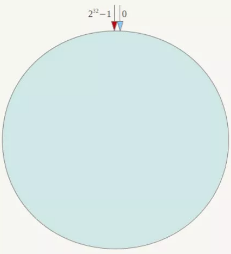
整个空间按顺时针方向组织,圆环的正上方的点代表0,0点右侧的第一个点代表1,以此类推,2、3、4、5、6……直到2^32 -1,也就是说0点左侧的第一个点代表2^32 -1, 0和2^32 -1在零点中方向重合,我们把这个由2^32个点组成的圆环称为Hash环
下一步将各个服务器使用Hash进行一个哈希,具体可以选择服务器的ip或主机名作为关键字进行哈希,这样每台机器就能确定其在哈希环上的位置,这里假设四台服务器使用ip地址哈希后在环空间的位置如下:
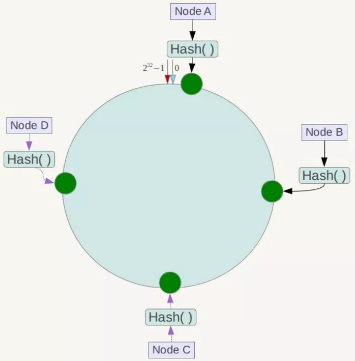
接下来使用如下算法定位数据访问到相应服务器:将数据key使用相同的函数Hash计算出哈希值,并确定此数据在环上的位置,从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器!
例如我们有Object A、Object B、Object C、Object D四个数据对象,经过哈希计算后,在环空间上的位置如下:
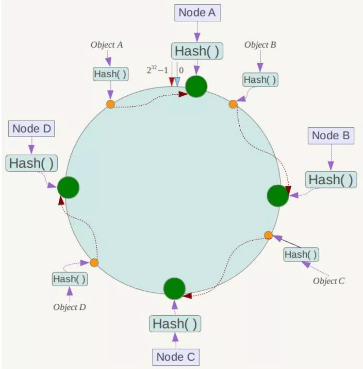
根据一致性Hash算法,数据A会被定为到Node A上,B被定为到Node B上,C被定为到Node C上,D被定为到Node D上
容错性
如果一个节点宕机了,会引起系统故障吗?
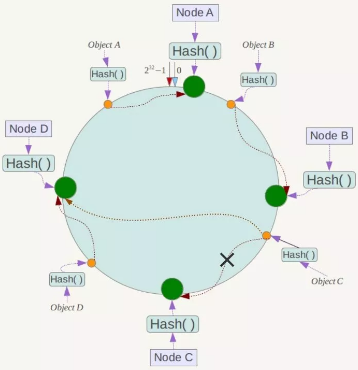
如上图,Node C不幸宕机,可以看到此时对象A、B、D不会受到影响,只有C对象被重定位到Node D。一般的,在一致性Hash算法中,如果一台服务器不可用,则受影响的数据仅仅是此服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,其它不会受到影响
扩展性
如果在系统中增加一台服务器Node X
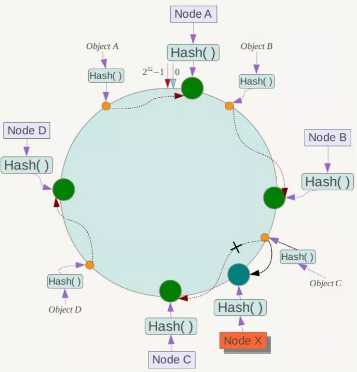
此时对象Object A、B、D不受影响,只有对象C需要重定位到新的Node X !一般的,在一致性Hash算法中,如果增加一台服务器,则受影响的数据仅仅是新服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,其它数据也不会受到影响
综上所述,一致性Hash算法对于节点的增减都只需重定位环空间中的一小部分数据,具有较好的容错性和可扩展性。
数据倾斜
一致性Hash算法在服务节点太少时,容易因为节点分部不均匀而造成数据倾斜(被缓存的对象大部分集中缓存在某一台服务器上)问题,例如系统中只有两台服务器,其环分布如下:
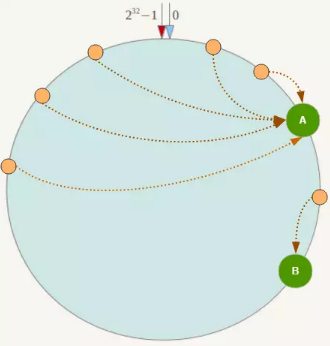
此时必然造成大量数据集中到Node A上,而只有极少量会定位到Node B上
然而,这又会造成一个“雪崩”的情况,即A节点由于承担了B节点的数据,所以A节点的负载会变高,A节点很容易也宕机,这样依次下去,这样造成整个集群都挂了
虚拟节点
计算机的任何问题都可以通过增加一个虚拟层来解决
解决上述数据倾斜问题,也可能通过使用虚拟层的手段:将每台物理缓存服务器虚拟为一组虚拟缓存服务器,将虚拟服务器的hash值放置在hash环上,Key在环上先找到虚拟服务器节点,再得到物理服务器的信息
例如上面的情况,可以为每台服务器计算三个虚拟节点,于是可以分别计算 “Node A#1”、“Node A#2”、“Node A#3”、“Node B#1”、“Node B#2”、“Node B#3”的哈希值,于是形成六个虚拟节点:
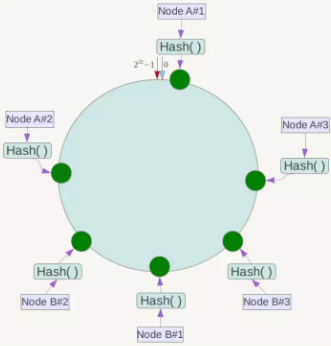
同时数据定位算法不变,只是多了一步虚拟节点到实际节点的映射,例如定位到“Node A#1”、“Node A#2”、“Node A#3”三个虚拟节点的数据均定位到Node A上。这样就解决了服务节点少时数据倾斜的问题
那么在实践中,一台物理服务器虚拟为多少个虚拟服务器节点合适呢?太多会影响性能,太少又会导致负载不均衡,一般说来,经验值是150,当然根据集群规模和负载均衡的精度需求,这个值应该根据具体情况具体对待
实现
判定哈希算法好坏的四个定义:
- 平衡性(Balance):平衡性是指哈希的结果能够尽可能分布到所有的缓冲中去,这样可以使得所有的缓冲空间都得到利用。很多哈希算法都能够满足这一条件
- 单调性(Monotonicity):单调性是指如果已经有一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲加入到系统中。哈希的结果应能够保证原有已分配的内容可以被映射到原有的或者新的缓冲中去,而不会被映射到旧的缓冲集合中的其他缓冲区
- 分散性(Spread):在分布式环境中,终端有可能看不到所有的缓冲,而是只能看到其中的一部分。当终端希望通过哈希过程将内容映射到缓冲上时,由于不同终端所见的缓冲范围有可能不同,从而导致哈希的结果不一致,最终的结果是相同的内容被不同的终端映射到不同的缓冲区中。这种情况显然是应该避免的,因为它导致相同内容被存储到不同缓冲中去,降低了系统存储的效率。分散性的定义就是上述情况发生的严重程度。好的哈希算法应能够尽量避免不一致的情况发生,也就是尽量降低分散性
- 负载(Load):负载问题实际上是从另一个角度看待分散性问题。既然不同的终端可能将相同的内容映射到不同的缓冲区中,那么对于一个特定的缓冲区而言,也可能被不同的用户映射为不同 的内容。与分散性一样,这种情况也是应当避免的,因此好的哈希算法应能够尽量降低缓冲的负荷
在具体实现时,主要考虑点选择适合的数据结构构造hash环
此数据结构的特点:插入与删除性能、快速找到特定元素的下一位
常见算法结构可以有回顾:
从时间复杂度方面选择,使用平衡二叉树数据结构,可以使得查找的时间复杂度降低为O(logN)
使用java,以TreeMap为例,TreeMap本身还提供了一个tailMap(K fromKey)方法,支持从红黑树中查找比fromKey大的值的集合,但并不需要遍历整个数据结构
1 | import java.util.Collection; |
dubbo实现
理解完理论,再扒一下工业级产品的运用,dubbo负载均衡策略之一ConsistentHashLoadBalance
1 | private final TreeMap<Long, Invoker<T>> virtualInvokers; |
整体思想是一样的,虚拟节点+TreeMap,但实现得更精致,使用MD5加密KEY,更加平衡性,整体的思路解释:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18//对所有节点,生成nCopies个虚拟结点
for(Node node : nodes) {
//每四个虚拟结点为一组,为什么这样?下面会说到
for(int i=0; i<nCopies / 4; i++) {
//getKeyForNode方法为这组虚拟结点得到惟一名称
byte[] digest=HashAlgorithm.computeMd5(getKeyForNode(node, i));
/** Md5是一个16字节长度的数组,将16字节的数组每四个字节一组,分别对应一个虚拟结点,这就是为什么上面把虚拟结点四个划分一组的原因*/
for(int h=0;h<4;h++) {
//对于每四个字节,组成一个long值数值,做为这个虚拟节点的在环中的惟一key
//结果转换为long类,这是因为生成的结果是一个32位数,若用int保存可能会产生负数。而一致性hash生成的逻辑环其hashCode的范围是在 0 - MAX_VALUE之间。因此为正整数,所以这里要强制转换为long类型,避免出现负数。
Long k = ((long)(digest[3+h*4]&0xFF) << 24)
| ((long)(digest[2+h*4]&0xFF) << 16)
| ((long)(digest[1+h*4]&0xFF) << 8)
| (digest[h*4]&0xFF);
allNodes.put(k, node);
}
}
}
总结
QA
为什么hash一致性的数据空间范围是2^32次方?
这个问题有两种答案,一是技术限制、一是实际场景:
- 因为,java中int的最大值是2^31-1最小值是-2^31,2^32刚好是无符号整形的最大值
- 因为一致性hash算法是来做服务器的负载均衡,而服务器的IP地址是32位,所以是2^32-1次方的数值空间
进一步追尾基础,为什么java中int的最大值是2^31-1最小值是-2^31?
因为,int的最大值最小值范围设定是因为一个int占4个字节,一个字节占8位,二进制中刚好是32位
根据算法特性,一致性hash是最好的选择吗?
下一篇介绍另一种实现google maglev hashing算法
参考资料
《大型网站技术架构》
对一致性Hash算法,Java代码实现的深入研究
