前言
这篇其实本来也打算放在《常识》系列中的,介绍一下分布式日志追踪系统,这在互联网界理论,技术,产品已经很成熟,国内外各大厂都有自己成熟的产品。是个不错的互联网门外汉科普知识点
微服务,已经火了多年,也已经落地实施。对服务的监控需求顺理成章。监控系统的本质其实也就是分布式日志追踪系统。就归类到《微服务》系列中吧
本篇大体内容
- 《微服务设计》第八章监控
- 监控理念Dapper
- 流行监控框架架构
- aspectj
《微服务》之监控
本来是说,要写个读书笔记的,但没有那么多完整的时间,正好学习监控,就把书拿出来,一并读了。理论结合实践,效果更好。
监控模型
三种监控模型
- 单一服务,单一服务器
- 单一服务,多个服务器
- 多个服务,多个服务器
单一服务单一服务器
- 主机状态
CPU、内存等,可以使用监控软件Nagios,Zabbix或者像New Relic这样的托管服务来帮助监控主机
- 服务状态
直接查看服务应用日志,或者web容器日志
单一服务多个服务器
- 主机状态
这种情况稍微复杂了一点,如前所述,如果我们想监控CPU,当CPU占用率过高时,如果这个问题发生在所有的服务器上,有可能是微服务本身的问题,但如果只发生在一台,则有可能是主机本身的问题。
我们需要关注每台服务器的日志数据,我们既想把数据聚合起来,又想深入分析每台主机,Nagios允许以这样的方式组织我们的主机。
- 服务状态
如果只有几个主机,可以用像ssh-multiplexers这样的工具,在多个主机上运行相同的命令。用一个大显示屏,运行grep “Error” app.log来定位错误。对于响应时间,可以在负载均衡器中跟踪,负载均衡器本身也需要跟踪。
多个服务多个服务器
这个情况就更复杂了,我们如何在多个主机上,成千上万行的日志中定位错误的原因?如果确定是一个服务器异常,还是一个系统性的问题?如何在多个主机跟踪一个错误的调用链,找出引起错误的原因?
答案是:从日志到应用程序指标,集中收集和聚合更可能多的数据
日志,更多的日志
需要将日志能够集中到一起方便使用
可以使用ELK
ELK由Elasticsearch、Logstash和Kibana三部分组件组成;
Elasticsearch是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
Logstash是一个完全开源的工具,它可以对你的日志进行收集、分析,并将其存储供以后使用
kibana 是一个开源和免费的工具,它可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助您汇总、分析和搜索重要数据日志

监控指标
系统指标:比如cpu 内存等,这些可以collectd进行收集
服务指标:比如接口调用次数,线程池空闲线程数等
语义指标:类似业务指标,比如订单量,活动用户数等
关联标识
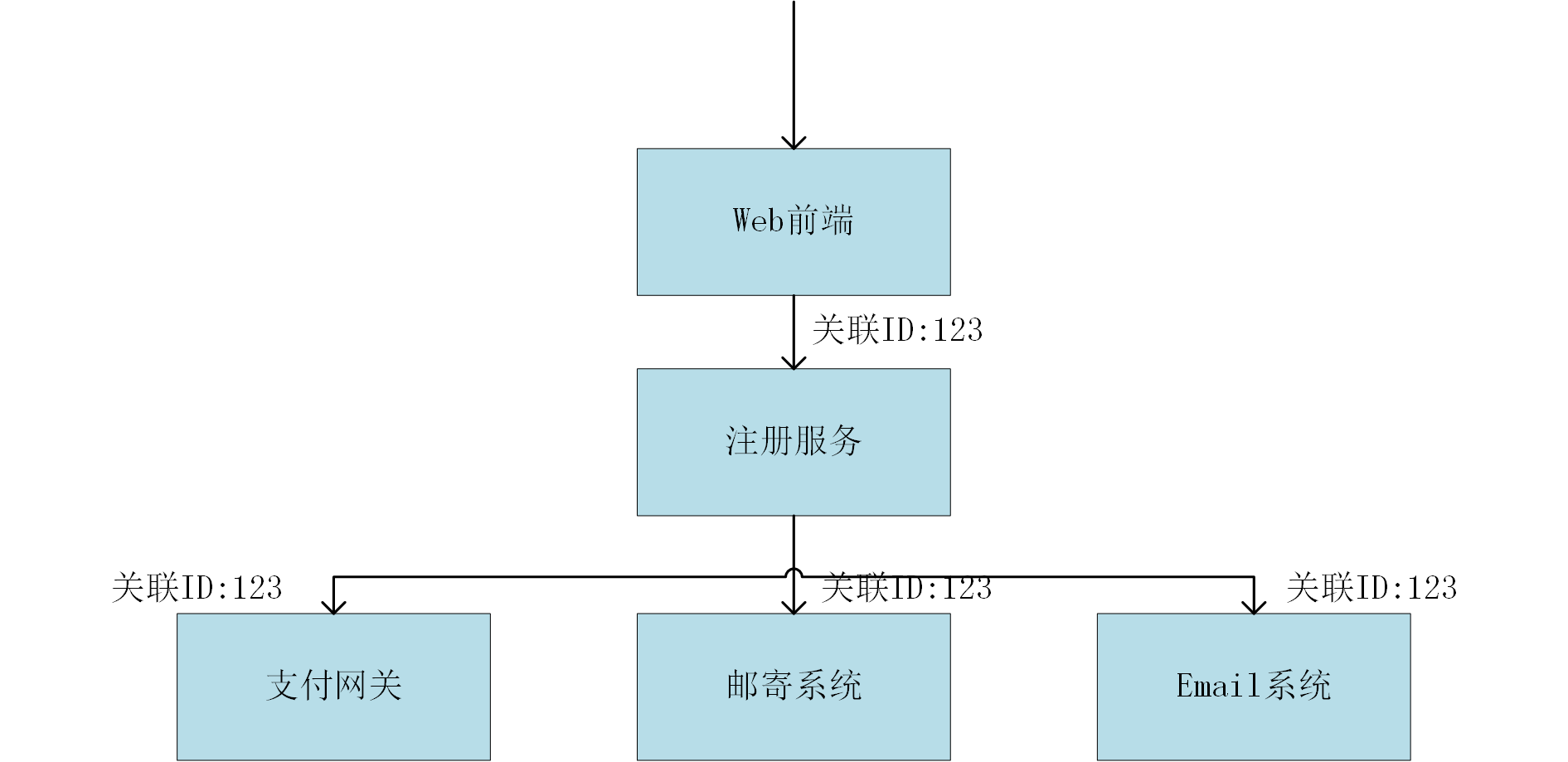
其实这就是服务追踪,调用链监控
因为微服务化后,各种系统之间的调用关系很复杂,因此排查一个问题会比较难受,你不需要一个系统一个系统去找问题。所以服务追踪就变得非常关键。他能够追踪一次会话的所有调用,哪里有了问题,一目了然
这个更详细的后面介绍google的dapper
其它
标准化:将监控api标准化。
考虑受众:谁看?运营还是开发?
更加实时:监控应该具有实时性,出问题第一时间反应。
避免级联危险:可以使用hystrix。
小结
对每个服务:跟踪请求响应时间、错误率和应用程序级指标;跟踪所有下游服务的健康状态,如调用时间、错误率;标准化如何收集和存储指标;以标准格式讲日志记录到一个标准位置;监控底层操作系统。
对系统:聚合CPU等主机层级的指标和程序级指标;确保指标存储工具可以在系统和服务级别做聚合,也能查看单台主机信息;指标存储工具允许维护数据足够长时间,以了解趋势;使用单个可查询工具对日志进行聚合和存储;强烈考虑标准化关联标识的使用;了解什么样的情况需要行动,并构造警报和仪表盘;调查对各种指标聚合和统一化的可能性。
Google Dapper
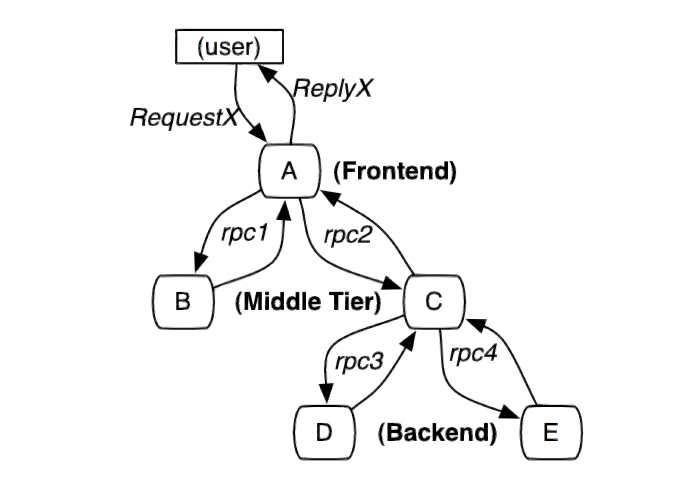
分布式服务的跟踪系统需要记录在一次特定的请求后系统中完成的所有工作的信息。举个例子,图展现的是一个和5台服务器相关的一个服务,包括:前端(A),两个中间层(B和C),以及两个后端(D和E)。当一个用户(这个用例的发起人)发起一个请求时,首先到达前端,然后发送两个RPC到服务器B和C。B会马上做出反应,但是C需要和后端的D和E交互之后再返还给A,由A来响应最初的请求。对于这样一个请求,简单实用的分布式跟踪的实现,就是为服务器上每一次你发送和接收动作来收集跟踪标识符(message identifiers)和时间戳(timestamped events)。
google dapper译文:http://bigbully.github.io/Dapper-translation/
Dapper有三个设计目标:
低消耗:跟踪系统对在线服务的影响应该做到足够小。
应用级的透明:对于应用的程序员来说,是不需要知道有跟踪系统这回事的。如果一个跟踪系统想生效,就必须需要依赖应用的开发者主动配合,那么这个跟踪系统显然是侵入性太强的。
延展性:Google至少在未来几年的服务和集群的规模,监控系统都应该能完全把控住。
监控框架
大的互联网公司都有自己的分布式跟踪系统,
比如Twitter的zipkin,淘宝的鹰眼,新浪的Watchman,京东的Hydra等
这些系统大多是基于dapper论文而来。
aspectj
监控系统,又名日志追踪系统,那主要还是打印日志嘛。
无侵入性的日志打印,AOP绝对是上选了
写了几个aspectj小示例
https://github.com/zhuxingsheng/aspectjdemo
当然,aspectj只是埋点,后面还有日志存储,实时计算,日志分析,监控展示
参考
http://www.cnblogs.com/gudi/p/6683653.html
