在《领域驱动设计》这本书里面,列举了三种可将业务逻辑建模为软件模型的模式,也就是大家常听说的事务脚本、贫血模型、DDD。
之前我还把这三种模式搞混淆了,too young too simple了。
举个简单的示例:
用户转帐,从一个帐户转到另一个帐户
事务脚本
Transaction Script

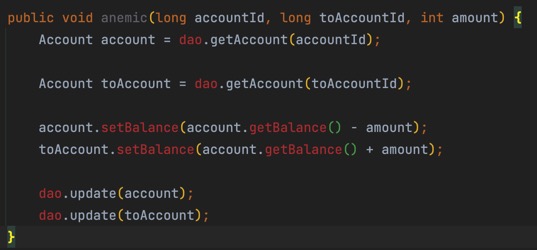
看代码,就是所有业务逻辑都放在了dao里面,有点类似于旧时代的存储过程。
事务脚本的思路有点类似于面向过程编程,要达到目标,需要哪些步骤,然后一步一步操作。业务逻辑被包含在一系列的操作行为中。
贫血模型
Anemic Model
贫血模型似乎从摒弃存储过程之后,把存储过程的搬迁到service中,实体对象与表一一对应。也被称为Table Module,表模块。
尤其有了ORM框架后,这种方式推上了高潮。
甚至在互联网场景的引领下,数据库的很多特性也放弃了,如外键。数据库不过就是存放数据的袋子,只要把数据能正确存放到里面就行了。
这种模型已经有很久的历史,如ER数据建模法。但在OO时代,被Martin Fowler列为反模式。
让人不得不思考一下,为什么OO时代,这种模型依然如此流行?
我们使用对象建模,就是把业务逻辑建模为 数据变化,然后把数据的改变和改变数据的行为放一起,数据变化,以及生命周期变化是业务的核心逻辑。
这个原因不得不回顾下面向对象的发展历史。在当前流行的面向对象语言诞生之前,第一代面向对象语言其实是Smalltalk。而且当时架构风格都是单体架构,这样就有一个相对现在隐藏的背景条件:在同一个节点中,能得到所有的上下文信息,都在内存中。
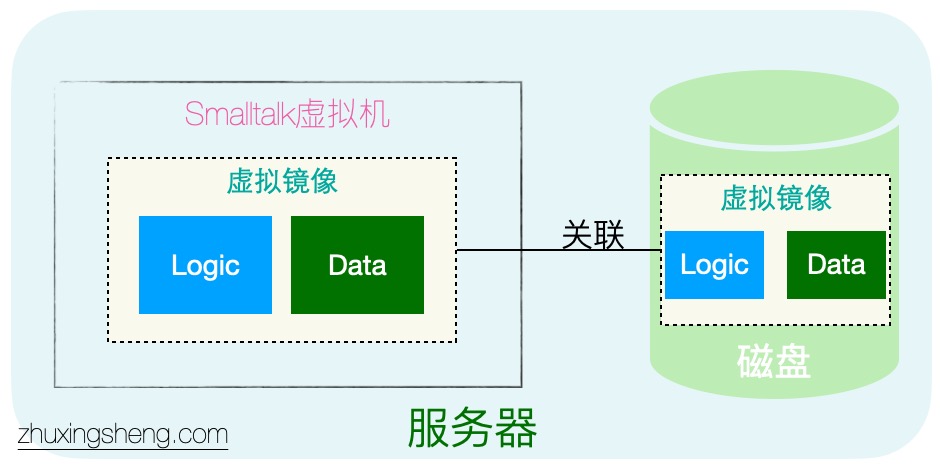
如上图,可以看出整个smalltalk的整体体系,除了虚拟机之外,还有虚拟镜像。虚拟镜像相当于虚拟机内存中数据持久化。每次虚拟机启动时,都会把虚拟镜像中的数据恢复到虚拟机内存中。
在这种背景下,在逻辑处理时,Collection相当于数据库,所有的数据都在里面,存取都很自然。
像现在的Java,C++并没有像smalltalk一样处理,时代来到了分层架构时代,经过了一系列的演变从最初的CS架构到三层,多层架构。
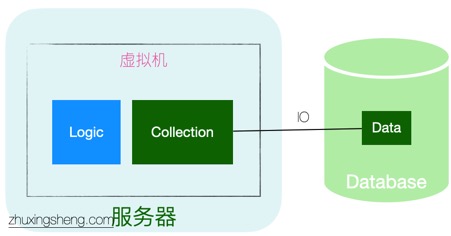
历史的发展都有延续性和局限性。虽然现代OO语言保留了集合类型,却去掉了虚拟镜像,集合数据不再完整地在内存中,而且由于分层架构的特性,逻辑与数据被切分开来,自然而然地当逻辑需要数据时,就会去DB获取数据。
到此,我们就明白了为什么贫血模型的火热原因。
而且,正因为有这种局限性,当我们想去构建OO充血模型时,这种分裂阻碍了我们。比如N+1性能问题,还需要对象追踪技术,如dirty tracking
DDD
Rich Model
在DDD是什么也有提到,当前软件复杂性越来越高,程序员其实不是在编写代码,而是在摸索业务领域知识。
如代码1
2
3public void setPassword(String password) {
this.password = password
}
password的确是被赋值了,但是为什么赋值,不知道。是注册了新用户,还是用户修改了密码。完全不知道是什么业务。导致当有新需求变更时,成本会越来越高。
为了不影响以前不知所云的代码,只能做累加,也就加重了代码不必要复杂性,整个软件交付会越来越难。
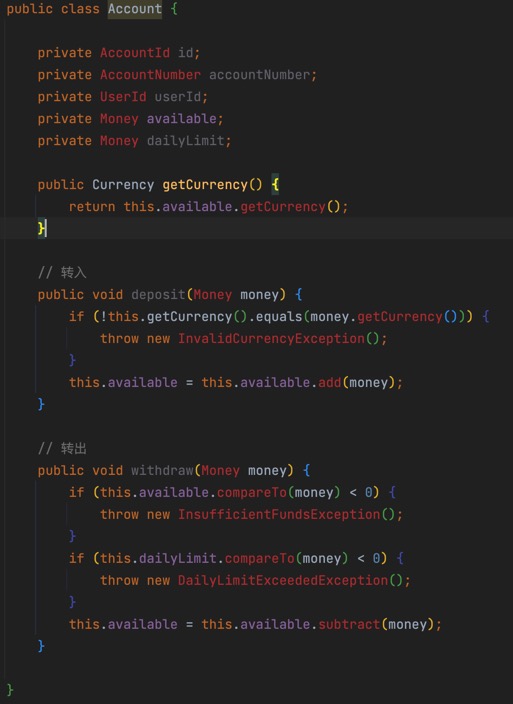
这种模式结合了上面两个种模式,事务脚本重视的是交互行为,贫血模式重视的是数据,而充血模式结合数据与行为,这也是面向对象建模的优势。
分离领域模型
怎么才能得到充血模型,Eric给出了思路,就是分离领域模型。
解决来自领域方面问题的软件部分通常只占整个软件系统的一小部分,这与它的重要性相比是不成比例的。
在面向对象的程序中,用户界面、数据库和其他支持代码,经常被直接写到业务对象中。在UI和数据库脚本的行为中嵌入额外的业务逻辑。这正是上面两种模式的做法。
当与领域相关的代码和大量的其他代码混在一起时,就很难阅读并理解了。对UI的简单改动就会改变业务逻辑。改变业务规则可能需要小心翼翼地跟踪UI代码、数据库代码或者其他的程序元素。实现一致的模型驱动对象变得不切实际,而且自动化测试也难以使用。如果在程序的每个行为中包括了所有的技术和逻辑,那么它必须很简单,否则难以理解。

DDD分层就是一种解决方式。
分层架构的目的是通过关注点分离来降低系统的复杂度,同时满足单一职责、高内聚、低耦合、提高可复用性和降低维护成本。
OO是最优解吗?
面向对象还是默认的最优模型构建方式吗?
这是一个有意思的问题,我也从没有深入思考过。说几个当前流行的一些架构风格。
当前DDD还是很火热的,大家都在追求充血模型。
最近我在实践中,会加一层facade层,不管是提供API,还是提供SDK。有点类似application service。
为系统提供一个统一门面,至于系统内部是用贫血模型,还是充血模型,对外部来讲是个黑盒,客户端不用关心。
那么再放大点,现在微服务架构是标配,我们只要知道服务在哪儿,提供了什么能力。内部怎么构建,不用关心。架构师的考虑点不再是一个个对象,而是一个个endpoint。
再就是像serverless架构风格,数据与行为是分开的,是以funcation为基本去构建服务。关注一个个function,process。
再比如大数据架构,像hadoop,数据是巨大的,搬迁是不太可能,通过mapreduce,我们是移动process。
经过这几种风格对比,随着AI的兴起,还会再出现新的模型方法,将来OO还是追求的最优解吗?
总结
实现业务架构的三种方式,贫血模型随处可见,而事务脚本与充血模型倒却难得一见。
事务脚本的确已经被抛弃,充血模型却是很多人爱不起来。看着很漂亮,但落地时又有性能、循环依赖、分层等等具体的问题。如何应对,且看专栏《DDD》。
